TheArchitectureofAgentMemory:FromChatLogstoQueryableKnowledge

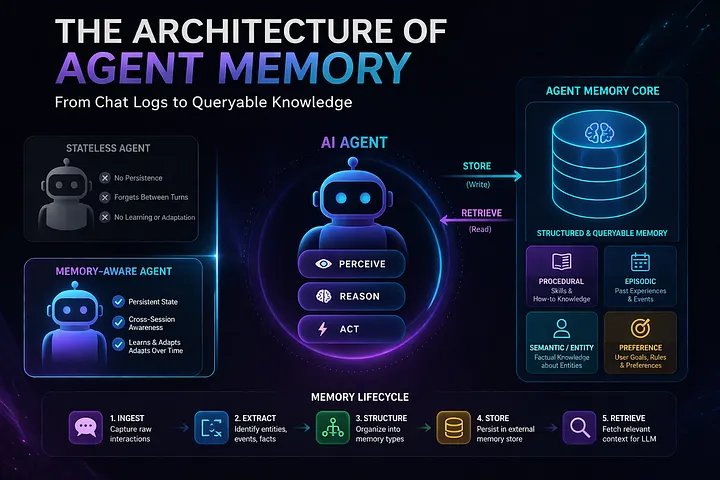
The Foundation of Agentic Memory
In the development of artificial intelligence, adding memory is the key factor that changes a simple, stateless agent into a complex entity that can remember. This change offers important continuity over time and across sessions.
Historically, developers have relied heavily on prompt and context engineering. This practice focuses on getting the most out of a single Large Language Model (LLM) call. However, as we work to create autonomous agents that can operate for weeks at a time, this approach of optimizing single calls does not meet our needs.
If you want systems that can operate reliably over long horizons, the focus has to move toward memory engineering. Long-term memory can’t be an afterthought — it needs to be treated as core infrastructure in the stack.
From an architectural standpoint, that means keeping memory outside the model, designing it for persistence from the start, and enforcing a clear, structured representation rather than letting it remain loosely defined.
With that kind of foundation in place, we move beyond agents that simply react to one-off prompts. The focus shifts to building systems that carry context forward — ones that can recall past interactions, refine their behavior over time, and maintain a consistent, ongoing sense of state.
Core Capabilities and the Architectural Foundation
Realizing true agentic memory involves mastering several complex technical capabilities. At an infrastructure level, developers must focus on:
- Building dedicated, persistent memory stores.
- Wiring up automated data extraction pipelines to process inputs.
- Implementing logic for handling contradictions that will inevitably arise within the memory over time.
A lot of early AI systems get by with a simple trick — just stuffing chat history back into the prompt. It works to a point, but it’s not real memory. If you’re serious about building agents that can actually remember and adapt, that approach falls short pretty quickly.
A proper memory-augmented agent needs a clearer architectural foundation. At a high level, it comes down to two core pieces: the agent stack, which handles behavior and execution, and the memory core, which is responsible for storing, structuring, and retrieving what the system learns over time.
Defining the AI Agent
Before you can design memory well, you need to be clear about what you’re augmenting. At a basic level, an AI agent is just a computational system that takes in signals from its environment, processes them, and acts — usually through tools or external interfaces. The decision-making layer underneath is driven by an LLM, which handles the reasoning and interpretation.
What separates more capable agents is the presence of an added memory layer. This isn’t just for storing past interactions — it enables the system to retain, retrieve, and apply information across sessions in a structured way. With that in place, the agent can operate with far less hand-holding, making decisions that stay aligned with its objectives while continuously building on what it has already learned.
The Bottleneck: The Stateless Agent
The difference becomes obvious when you put a memory-enabled agent next to a stateless one. Both follow the same basic loop — perceive, reason, act — but only one of them can carry context forward. A memory-backed agent turns individual interactions into a continuous thread, instead of treating each turn as a reset.
A stateless agent, on the other hand, works in isolation every time. There’s no linkage between turns, no retained context. In multi-step interactions, that limitation shows up quickly — it can’t keep track of what’s already been said or done.
The result is a fragile experience. Try referencing something from earlier in a long conversation — say, 10–15 turns back — and the system just stalls or forces you to restate everything. That constant loss of context breaks flow and makes anything beyond short, single-step tasks impractical. Without a proper memory layer, long-horizon workflows don’t really hold up.
The Architecture of Amnesia: Anatomy of a Stateless Agent
To see why memory engineering matters, it helps to look closely at what it’s replacing — the stateless agent.
On the surface, a stateless setup does everything you’d expect. It takes in input, passes it through an LLM for reasoning, and produces a coherent response. The basic loop — perception, reasoning, action — works without issue.
The problem is structural. There’s no persistence. Each interaction is treated as a clean slate, and once a response is generated, whatever context existed during that step is effectively discarded. There’s no mechanism to carry forward state, recall prior decisions, or build on earlier interactions. Over time, that limitation becomes the bottleneck for anything that requires continuity.
The Technical Debt of Statelessness
Relying on a stateless architecture for anything beyond simple, zero-shot Q&A introduces massive technical debt and operational blockers. The core limitations include:
- Inability to Execute Long-Horizon Tasks: Because the agent’s state resets after every interaction, it is mathematically impossible for it to autonomously manage multi-step workflows that require sustained context over hours or days.
- Zero Cross-Session Context Awareness: The agent treats every new session as its very first interaction. There is absolutely no context awareness bridging separate sessions.
- No Learning or Adaptation: A true autonomous system must improve over time. A stateless agent possesses no learning or adaptation abilities whatsoever.
- Static Intelligence: Even if a user explicitly provides a critical new fact during a session, the system will not use that new information to inform any subsequent, isolated interactions .
- Exorbitant Operational Costs (Context Stuffing): This is the most severe infrastructural penalty. To simulate memory in a stateless system, developers are forced to use a brute-force technique known as “Context Stuffing.” Every single time the user sends a message, the application layer must retrieve the entire historical chat log and stuff it back into the LLM’s context window.
- The Burden of Augmentation Continuity: Because of context stuffing, the system demands heavy augmentation continuity for every single turn. This burns through token limits exponentially, spikes API costs, and drastically degrades latency and response quality as the context window approaches its limits.
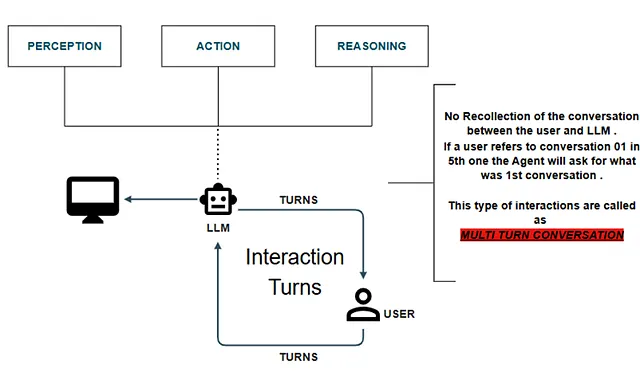
The Paradigm Shift: Memory-Augmented Architectures
To resolve the extreme operational costs and cognitive amnesia of stateless models, system architects introduce the Memory-Augmented Agent.
This architecture fundamentally alters the execution loop. Instead of a linear path of Perception → Reasoning → Action, the system injects a persistent Memory layer directly into the flow. By routing interaction history into an external Database (DB) for all subsequent turns, the agent can actively retrieve historical states .
Integrating this continuous memory loop physically augments the agent’s perception, reasoning, and action capabilities. The systemic benefits of this architectural shift are profound:
- Context Optimization: It drastically improves token efficiency and reduces the need for aggressive context stuffing .
- Workflow Persistence: Persistent memory enables the execution of complex, multistep workflows .
- Sustained Autonomy: It unlocks the ability to perform long-horizon tasks and exhibit adaptive behaviors.
- Cost Reduction: By preventing redundant token usage, operational costs drop significantly.
- Cross-Session Awareness: It maintains a sustained context awareness that persists across completely distinct user sessions .
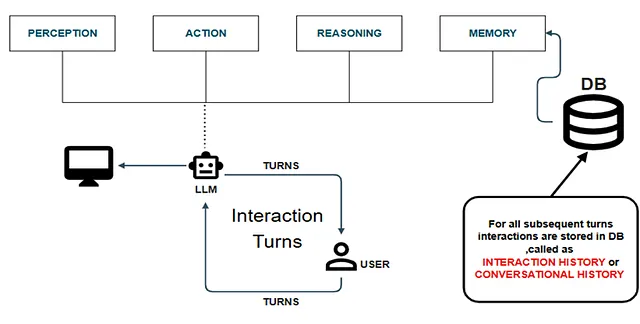
The “Naive” Implementation: Conversational Memory
While the shift to augmented memory is necessary, the most basic implementation of this is what engineers refer to as the Naive Memory-Augmented Agent.
Under the hood, it’s still a stateless system — just with a database bolted on to give the illusion of memory. What it’s really doing is repeatedly pulling past interactions and feeding them back in as context.
That approach does improve baseline reliability. At least the system can reference earlier exchanges and maintain some continuity across turns. But it’s still a workaround — there’s no true notion of state, just repeated reconstruction of it from stored history.
Anatomy of Conversational Memory (CM)
The core engine of this naive architecture is Conversational Memory (CM). This is the simplest structural form of agent memory, relying entirely on a time-ordered interaction history.
Here is exactly how data flows and is structured within a CM system:
- Data Capture: The system captures the back-and-forth information, recording the specific user actions and interactions taken .
- External Storage: This data is packaged with specific attributes and precise timestamps, then written directly to an external DB .
- Context Window Assembly: When a new turn initiates, the application layer dynamically constructs the LLM Context Window. It pulls together:
- i. The static System Prompt & Instructions.
- ii. The Multi-turn past interactions queried from the External DB .
- iii. The current User Prompt.
- iv. The Assistant’s message.The static System Prompt & Instructions.
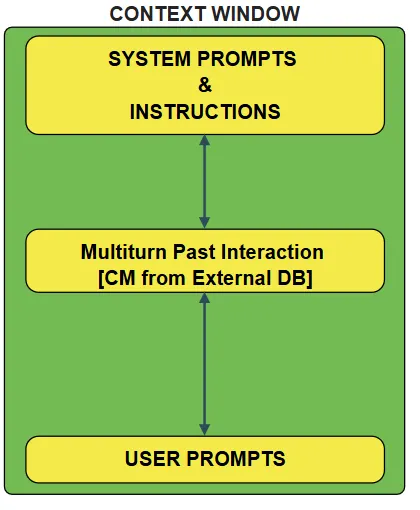
This naive “context + memory” setup does fix the immediate issue of forgetting across turns, but at its core it’s still just an automated chat log. You’re replaying history, not building a system that actually understands or evolves from it.
That becomes a bottleneck pretty quickly. Once you move toward more complex, workflow-driven agents, raw conversational history isn’t enough. It lacks structure, prioritization, and intent — so the system struggles to scale beyond simple continuity into something that feels genuinely intelligent.
Beyond Conversational Memory: The Need for Structured Knowledge
Conversational memory does address the immediate issue of losing context across turns, but it doesn’t get you to real autonomy. If the goal is to build capable, self-directed agents, relying purely on interaction history isn’t enough — you have to move beyond it.
The limitation is structural. Raw chat logs don’t scale well: they’re noisy, unstructured, and hard to reason over. As the system grows, this turns into a bottleneck. The way forward is to stop treating memory as a transcript and start treating it as data — something that’s extracted, organized, and explicitly structured for retrieval and use.
1. The Finite Context vs. Infinite Relationships
The core issue with conversational memory is a mismatch in scope. Chat windows are finite; user relationships aren’t.
If an agent only retains what fits inside a rolling conversation log, it never builds a stable understanding of the user. Context gets truncated, and anything outside the immediate window is effectively lost. That makes it impossible to maintain continuity at a relationship level.
The fix is architectural. Instead of treating memory as raw dialogue, the system needs to link interactions to structured, external representations. That means pulling out meaningful signals and anchoring them to persistent data.
A straightforward example is entity extraction. Rather than storing a line like “I moved to New York with Sarah,” the system should break it down — identify the location, the person, and the relationship between them — and persist those as structured records. Over time, this builds a connected graph of the user’s context, not just a sequence of past messages.
2. Cross-Session Data Extraction
Another limitation is that useful information rarely shows up in one clean, self-contained interaction. In practice, users reveal preferences, constraints, and goals gradually — spread across multiple sessions over time.
If the system only looks at individual conversations, it misses those signals entirely. The architecture needs a way to aggregate and consolidate them.
That’s where extraction pipelines come in. Instead of treating dialogue as the end state, the system continuously processes it — pulling out relevant details, normalizing them, and storing them in a form that can be reused later. This is what allows the agent to carry context across sessions in a reliable way, rather than depending on whatever happens to be present in the current prompt.
3. From Chat Logs to Queryable Knowledge
At the end of the day, basic conversational memory is just a record of interactions — flat chat logs. That’s fine for continuity, but it doesn’t translate well to execution.
Autonomous agents aren’t just holding conversations; they’re expected to carry out tasks. For that, transcripts aren’t enough. What they need is structured, queryable knowledge that can be directly used during decision-making.
Once you move into workflow-driven systems, this gap becomes obvious. Execution happens as a sequence of defined steps within a larger process, and a linear chat history doesn’t provide the right abstraction for deciding what comes next. It lacks state, intent, and clear mappings to outcomes.
In a more mature setup, memory stops being a passive log and becomes an active component of the system. The data is distilled into forms that are explicitly useful — entities, constraints, intermediate results, outcomes — and tied directly to execution. That’s what allows the agent to operate reliably over longer horizons without depending on conversational replay.
The Taxonomy of Agentic Memory
To successfully transition from flat chat logs to structured, queryable knowledge, system architects must categorize extracted data into distinct Forms of Agent Memory. Each form serves a specific operational purpose within the agent’s execution loop, ranging from highly volatile context to permanent, experiential knowledge.
1. Session-Based Memory
This is the baseline operational layer, strictly bound to the LLM Context Window. An LLM can operate effectively within this immediate scope, but the memory is highly volatile; it is entirely lost after an interaction session concludes.
2. Semantic Cache (Short-Term / Working Memory)
Operating as the agent’s working memory, this is a sophisticated caching mechanism that actively leverages vector search. It stores the exact responses previously received from the inference provider. By utilizing vector similarity, these cached responses are instantly retrieved and used for similar queries in subsequent interactions, which drastically reduces API latency and token costs.
3. Procedural / Semantic Memory
This is the foundational layer for agent autonomy, acting as the system’s “experience”. Procedural memory captures the specific workflow steps and interactions an agent has taken to successfully achieve an objective. A prime example of this is Tool Calling: tools act as a form of external memory that can be referenced by the agent. By saving these pathways, an entire specific toolbox can be dynamically pulled into a subsequent interaction based on the agent’s past execution experience.
4. Entity Memory
Moving away from conversational data, Entity Memory acts as a dedicated, structured Knowledge Base. It is engineered to house external knowledge, strictly domain-specific knowledge, and persistent system personas.
5. Episodic Memory (Long-Term)
This represents the consolidated, long-term history of the agent. Instead of relying on raw, token-heavy conversational logs, episodic memory utilizes highly compressed conversational summaries to maintain a dense, efficient record of past interactions over time.
What is Agent Memory?
Moving beyond the theoretical taxonomy of memory types, we must define what this actually looks like at an engineering level.
Fundamentally, Agent Memory is a deliberate composition of system components combined with specific architectural components. This architecture is not just for logging data; it is specifically designed to enable an AI agent to continuously adapt and learn.
At a technical level, this composition relies on three primary system components:
- The Embedding Model
- Databases (DBs)
- The Large Language Model (LLM)
These physical components are orchestrated by specific control mechanisms, which essentially function as the software behaviors of the memory system.
Together, this integrated infrastructure actively enables an agent to store, retrieve, and efficiently recall information on demand. By establishing this continuous loop of stateful storage and retrieval, the system successfully allows the agent to genuinely adapt to live interactions and iteratively learn over time.
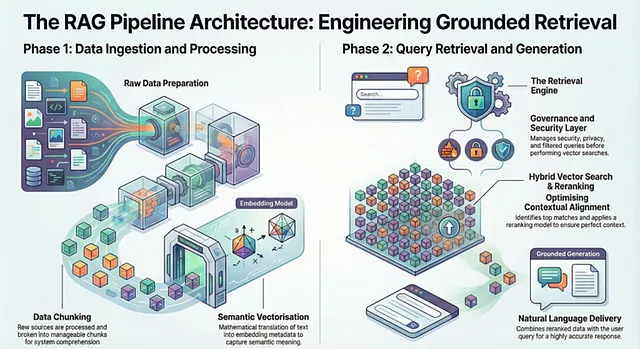
The Engineering of Retrieval: The RAG Pipeline
To transform static data into actionable agent memory, the architecture relies heavily on the RAG (Retrieval-Augmented Generation) Pipeline. This pipeline is the engine that dictates how external knowledge is ingested, vectorized, and retrieved during an active interaction.
Data Ingestion and Processing
The lifecycle begins with raw data sources. Before this data can be understood by the system, it must be passed through a Data Processing (DP) pipeline, where techniques like chunking are applied.
Once chunked, the data passes through an Embedding Model. This step is critical because it extracts the semantic meaning of the data and generates embedding metadata. Following this mathematical translation, the vectors complete the data ingestion phase.
Query Execution and The Retrieval Engine
When a user submits a query, that input must be translated into the same mathematical space. The user query is passed into the embedding model to create a specific query vector.
Before raw retrieval occurs, the query passes through a sophisticated Retrieval Engine. This engine acts as a governance layer, handling security, privacy, filtered queries, and multimodality.
Vector Search and Grounded Generation
Once cleared, the system executes Query Vector Retrieval against a single database. It performs a Vector Search — or a Hybrid search approach — to identify and match the Top K rows against the query vector.
Because standard vector similarity isn’t always perfectly aligned with context, the retrieved rows are passed through a Reranking Model. Finally, these reranked rows are combined with the original user query.
The end result is a natural language response delivered to the user that is highly accurate and strictly grounded in domain-specific data.
Integrating RAG with Agent Memory
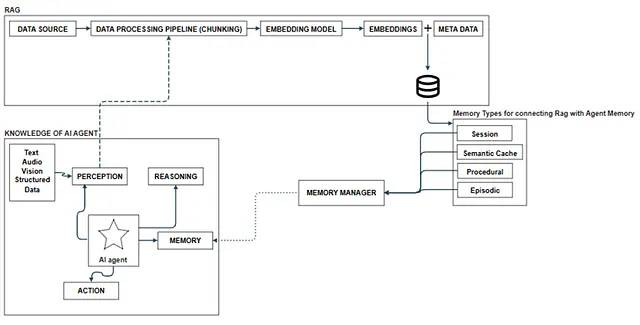
While a standalone Retrieval-Augmented Generation (RAG) pipeline is powerful, connecting it directly to an autonomous agent requires a dedicated architectural bridge.
The foundation of this integration starts with the “Knowledge of Agent”. Various data sources — including Text, Audio, Vision, and Structured Data — are ingested into the system. This raw information passes through a Data Processing (DP) pipeline specifically for chunking. It then routes through an Embedding Model to create vectorized embedding data, which completes the data ingestion phase into a Single DB.
Bridging the Cognitive Loop
To successfully connect the DB of RAG to the actual agent memory, the system needs a specific abstraction layer for memory types. The AI agent operates using a continuous loop of Perception, Reasoning, Action, and Memory, driven by the LLM.
When the agent decides to execute an Action based on its reasoning, it utilizes specific technical execution pathways such as Functions, Rest APIs, Scripts, Skills, and MCP.
The Memory Manager Abstraction
The critical abstraction layer that makes this entire RAG-to-Agent integration possible is the Memory Manager. This component is responsible for organizing the database into specific, functional tables. It specifically categorizes and manages the distinct Session, Episodic, and Procedural forms of the database.
Ultimately, the AI agent gains access to all of these complex retrieval capabilities by connecting to the Memory Manager through tools. The system provides these structured data flows as native capabilities to the agent via its memory, seamlessly merging the external RAG pipeline with autonomous execution.
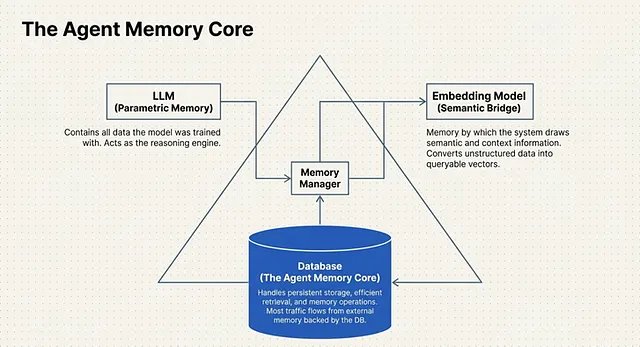
The Agent Memory Core (AMC): Infrastructure for Autonomy
To effectively bridge the gap between volatile context windows and long-term learning, system architects rely on a dedicated structural pattern known as the Agent Memory Core (AMC).
The AMC is not merely a supplementary feature; it is the primary infrastructure component of an entire agentic system . It acts as the central orchestrator responsible for managing the complete lifecycle of agent memory .
Architecturally, an Agentic System’s memory core is broken down into 3 Main Components that operate in tandem:
1. The LLM (Parametric Memory)
While we often think of the Large Language Model (LLM) strictly as the reasoning engine, within the AMC framework, it serves a specific memory function. The LLM acts as the system’s Parametric Memory. This represents the static baseline of all the data and knowledge the model has been explicitly trained with prior to deployment . It is the foundational world-knowledge the agent uses to interpret new inputs.
2. The Embedding Model (Semantic Engine)
If the LLM is the baseline knowledge, the Embedding Model is the translation layer . This component represents the memory by which the system can draw out critical semantic and context information . Whenever new data is introduced or a user provides an input, the Embedding Model mathematically evaluates it, generating an embedding that captures its deeper contextual weight so it can be accurately stored and searched.
3. The Database (External Memory)
The final and most dynamic component is the Database. This is the physical infrastructure where the active agent memory is actually located (or could be said to be located). Because parametric memory (the LLM) is static, most new input and ongoing interaction data must be stored in and retrieved from this external memory layer, which is strictly backed by a DB.
The Functional Output of the AMC
By combining these three components, the AMC provides a robust database layer that successfully handles persistent storage, efficient retrieval, and complex memory operations .
Ultimately, it is this specific architectural core that enables AI agents to continuously adapt to new information, actively learn from ongoing interactions, and maintain highly consistent performance across multiple, disconnected sessions .
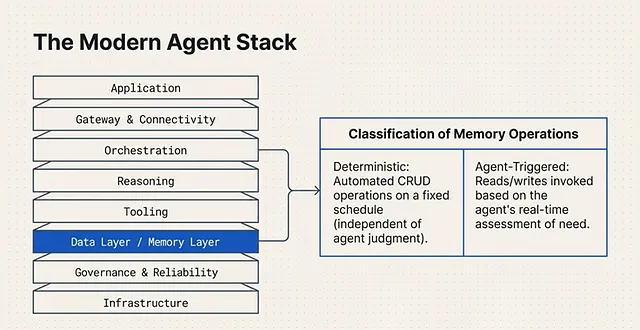
The Modern Agent Stack: Layered Architecture for Production
Building an autonomous agent requires more than just connecting an LLM to a database. To ensure that an AI agent performs reliably and efficiently in a production environment, developers rely on a formalized architecture known as the Agent Stack.
At its core, the Modern Agent Stack is a layered composition of tools and technologies. Together, these components form a cohesive system architecture that strictly enables the execution of an AI agent or a broader Agentic System.
To manage the complex dependencies between reasoning, memory, and execution, the stack is divided into 3 Main Layers:
1. The Application Layer
This is the top-most tier of the stack, responsible for user interaction and high-level routing. It consists of:
- The Application: The primary interface or environment where the agent operates.
- Gateway & Orchestration: The systems that manage incoming requests, route them to the appropriate models, and orchestrate the overall multi-step workflow of the agent.
2. The Data Layer / Memory Layer
This is the cognitive and operational core of the agent. It houses the critical systems required for the agent to think and act:
- Reasoning: The LLM processing capabilities.
- Tooling: The procedural memory and executable functions the agent can call upon.
- Data Layer: The active databases and embedding models where semantic and episodic memory reside.
3. The Infrastructure Layer
The foundational tier that ensures the agent can operate continuously and securely at scale. It includes:
- Governance & Reliability: The guardrails, monitoring systems, and evaluation protocols that keep the agent’s behavior aligned and consistent.
- Infrastructure: The underlying compute resources, vector databases, and hosting environments that physically power the Agentic System.
By organizing the system into these three distinct layers, engineers can isolate memory operations within the Data Layer while allowing the Orchestration layer to manage the actual execution flow.
Orchestrating Memory: Control Logic and Operations
With the Agent Stack successfully divided into the Application layer, Memory layer, and Infrastructure layer, the system requires a governing intelligence to manage the flow of data. This is where the Control Logic comes into play.
The control logic within the Agent Stack acts as the decision-making engine that dictates exactly what data becomes memory. During the execution of an Agent architecture, this logic determines how that memory is structured, how it is continuously updated, and precisely when it should be recalled to aid the LLM.
To physically execute these decisions, the architecture relies on two primary components: the Memory Core and the Memory Manager. Together, they facilitate Memory-Augmented Agent Behaviour, driving system continuity and enabling long-horizon adaptation.
Classification of Memory Operations
How does the system actually execute a read or a write? The classification of a memory operation depends entirely on how that specific operation is called into action. In a mature memory architecture, these operations are split into two distinct paradigms:
1. Deterministic Memory Operations These are foundational, hard-coded memory reads and writes. They run automatically on a fixed schedule or are triggered by predefined conditions set by the developers. Crucially, deterministic operations execute completely independent of the agent’s own judgment or reasoning.
2. Agent-Triggered Memory Operations This is where true autonomy begins. Agent-triggered operations are dynamic memory reads and writes that the agent explicitly decides to invoke. Instead of relying on a hard-coded schedule, the agent utilizes its reasoning capabilities to execute these operations based on its own real-time assessment of need.
By mastering both deterministic logging and agent-triggered recall, engineers can build systems that autonomously manage their own cognitive load.
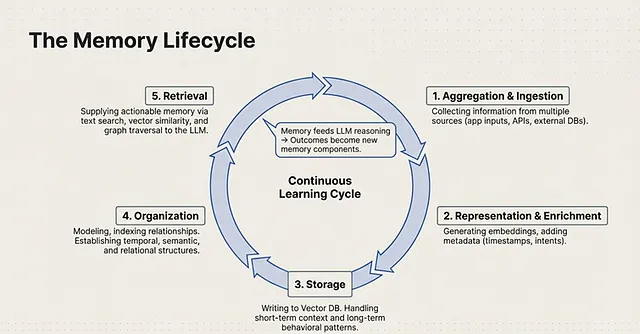
The Memory Life Cycle: A Continuous Learning Engine
To truly engineer an autonomous agent, memory cannot be static; it must operate as a Continuous Learning Cycle. In this architecture, historical memory actively feeds the LLM’s reasoning processes, and the subsequent outcomes generated by the LLM become new memory components themselves.
This systematic flow of data is formalized as the Memory Life Cycle. It dictates exactly how information is ingested, processed, and recalled through five distinct stages:
1. Aggregation & Ingestion
The cycle begins with the collection of information from multiple sources. Agents ingest raw data originating from various channels, such as application inputs, external databases, and APIs.
2. Representation & Metadata Enrichment
Raw data is useless to an LLM without proper context. In this phase, the data undergoes representation and metadata enrichment. The system generates vector embeddings and attaches critical metadata, including timestamps, intent semantics, and core information.
3. Storage
Once enriched, the data moves into the storage layer, utilizing Data Memory systems such as an Oracle AI Database. This infrastructure is designed to handle multiple temporal scopes, storing short-form context, medium-term patterns, and long-term behaviour.
4. Organization
Simply storing data in a database is insufficient for rapid recall; it must be structured. The organization phase involves modeling, indexing, and establishing relationships. Engineers must specify temporal, semantic, and relational indexing to map how different memory units relate to one another.
5. Retrieval
The final stage transforms dormant data into Actionable Memory. When the agent needs context, the system executes retrieval using advanced mechanisms like text search, vectors similarity, and graph traversal.
The Execution Loop
Running in parallel to this storage pipeline is the actual execution loop. The system uses augmentation to inject this retrieved memory and context directly into the LLM. The LLM then performs inference, processing, and reasoning to generate an output. Finally, this output undergoes serialization before being fed back into the continuous learning cycle as newly retrieved memory.
The Multidisciplinary Science of Memory Engineering
Building a robust memory lifecycle is not a single, isolated skill. At its core, Memory Engineering is a deliberate combination of existing disciplines. By taking the best practices and foundational principles from these established fields, developers enable the highly efficient implementation of memory operations within AI agents.
To architect these systems, engineering teams must synthesize four distinct technical domains:
1. Database Engineering
This discipline forms the structural foundation of the memory system. It ensures data integrity and scalable access by relying on Persistent Storage, ACID Transactions, Typed Schemas, and a Multi Store Architecture.
2. Agent Engineering
This focuses on the behavioral and cognitive loops of the AI itself. It involves designing the Memory Lifecycle, implementing Write-Back Loops, and engineering pipelines for Memory Extraction and Autonomous Consolidation, alongside Context Aware Routing.
3. Machine Learning
This domain handles the underlying models that process and interpret the stored data. Key practices include deploying Embedding Models, Fine-Tuning Small Language Models (SLMs), strict Model Versioning, implementing Reranking Pipelines, and facilitating Continual Learning mechanisms.
4. Information Retrieval Engineering
Storing data is useless if the agent cannot find it instantly. This discipline focuses on data extraction using Hybrid Search, advanced Vector Indexes (like HNSW), Relevance Ranking, precise Context Assembly, and ongoing Query Optimization.
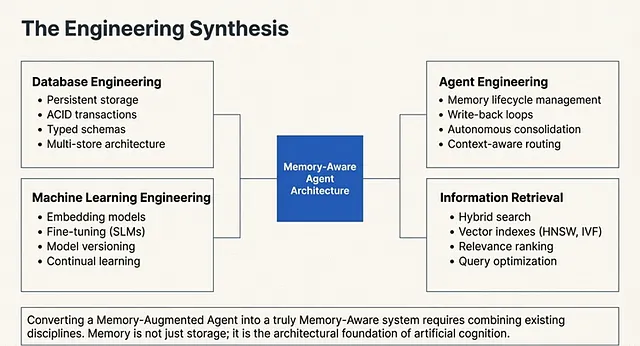
The Architectural Evolution
When a system successfully integrates the principles from all four of these disciplines, a fundamental transformation occurs. The architecture evolves past a basic “Memory Augmented Agent” and matures into a fully autonomous “Memory Aware Agent”.
The Memory Aware Agent: Context Segmentation and Autonomy
When the engineering disciplines discussed previously are fully synthesized, the architecture evolves from a Naive Memory Augmented Agent into a true Memory Aware Agent . The defining characteristic of this advanced system is the addition of explicit memory type allocation.
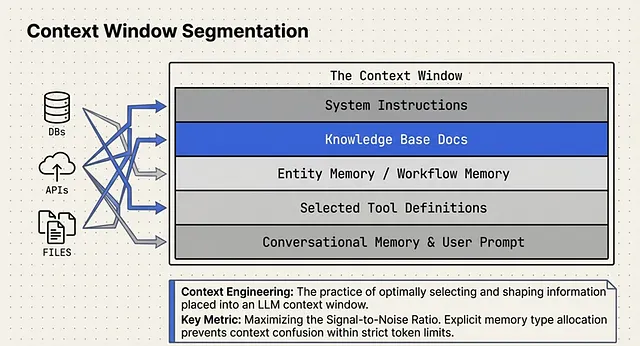
Instead of dumping all retrieved data into a single block of text, the architecture utilizes Context Window Segmentation. The LLM’s context window is strictly divided into portions or partitions allocated for specific memory types. These segmented partitions include conversational memory, workflow memory, toolbox memory, and other forms of agent memory .
Crucially, the agent achieves Memory Store Awareness directly via the System Prompt. Because it understands its own memory architecture, it becomes capable of advanced memory lifecycle reasoning. This enables Agent-triggered memory operations, meaning the agent could store, retrieve, read, and explicitly forget memory entirely at its own discretion .
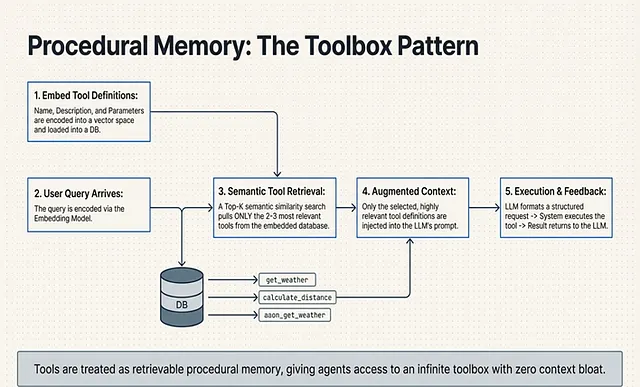
The Toolbox Pattern: Scaling Procedural Memory
This partitioned, self-aware architecture completely changes how an agent interacts with its environment, particularly when it comes to tool usage. In complex enterprise environments, an agent requires access to hundreds of tools. Historically, developers attempted staffing every tool definition into the prompt, which destroys the context window .
To solve this scaling bottleneck, advanced architectures treat tools as Procedural Memory.
This is implemented using the Toolbox Pattern. Instead of putting all tool definitions into the context window, the system is designed to store them in a memory-backed store . At inference time, the system leverages embedding and semantic search to retrieve only the relevant ones . This allows the LLM to select the most optimal tools at any given time dynamically .
By treating tool definitions as retrievable sources rather than static prompt text, the LLM transitions into becoming truly tool-aware for task completion. It fundamentally changes how the agent is able to perceive the tools they have at their disposal, pulling only the exact procedural memory required for the current reasoning step .
The Mechanics of the Tool Calling Pattern
To understand how procedural memory is utilized, we must first break down the baseline execution flow of the Tool Calling pattern (often referred to as function calling).
A critical architectural distinction to make is that within this pattern, the Large Language Model (LLM) does not directly execute code. The LLM is strictly a reasoning engine. Instead, it acts as a router that generates a structured request for a tool . The actual execution of the code is handled entirely by the Application Runtime .
The 6-Step Execution Flow
The interaction between the user, the LLM, and the application’s runtime follows a strict, sequential pipeline:
- Tool Definitions: Before any interaction occurs, the system must establish the tool definitions. This includes the tool’s Name, a Description on exactly how the tool has to be called, and the required Parameters.
- User Query: The cycle initiates when a User Query is passed into the system.
- LLM Calls a Tool: The LLM evaluates the query against its available definitions and generates a structured request to call a tool. For example, it outputs a JSON payload like: { “name”: “get-weather”, “description”: “Return forecast for location and date”, “parameters”: { … } } .
- System Execution: The application’s runtime catches this structured request and physically executes the tool on behalf of the LLM.
- Return Results: Once the code runs, the system returns the Result (and any relevant feedback) back into the LLM’s context window .
- Final Generation: Armed with the newly retrieved external data, the LLM generates a final, grounded Response for the user.
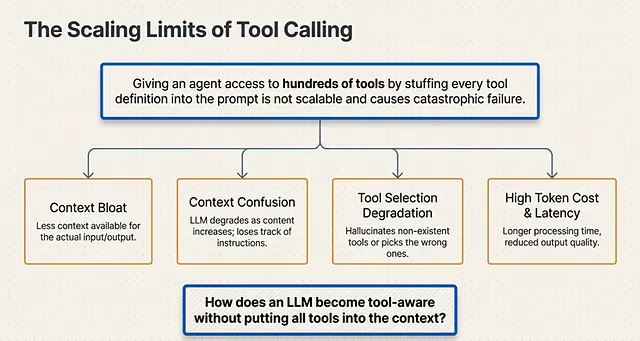
While this 6-step loop works perfectly for a handful of functions, it breaks down catastrophically when an agent needs access to hundreds of enterprise tools.
The Limitations of Tool Calling
In theory, the equation for agent capability is simple: giving an LLM more info and more tools should lead to better responses. However, in a production environment, this linear thinking breaks down immediately because the LLM context window is strictly limited.
Developers quickly realize they cannot stuff all the available tools into the context. Relying on prompt-based tool definitions simply isn’t scalable, introducing massive cost and latency problems. This exact bottleneck is where a lot of agents fail.
The Degradation Cascade
When you force too many tool schemas into a single prompt, the architecture suffers from a cascading failure known as Context Bloat. This bloat triggers several systemic issues:
- Context Confusion & Tool Selection Degradation: The LLM loses its ability to accurately distinguish between similar tools, leading to hallucinations or incorrect tool selection.
- High Token Cost & Latency Increase: Processing massive prompts for every single turn drives up token costs exponentially and causes severe performance degradation.
- Reduced Output Quality: Because the tool definitions consume the majority of the token limit, there is less context available for the actual user input and the output being produced. Ultimately, the content degrades, it takes a longer time to process, and the final output quality is significantly reduced.
Scaling Tool Calls in Agents
To bypass these limitations, Memory Engineers completely remove the tool definitions from the static prompt and move them into an Encoded Vector Space. This transforms tools into queryable procedural memory.
Here is the exact execution flow for scaling tool calls:
- Embedding: The raw NLP tool definitions are passed through an embedding model.
- Storage: These vectorized tools are loaded directly into a DB.
- Encoding the Input: When a user query is received, the system encodes the query itself.
- Retrieval: The system executes a Semantic Search (specifically a Similarity Search or Top-K search) against the database of tools.
- Selection: Only the best, most relevant tools are selected and injected into the LLM’s context window for that specific turn.
- Execution: Finally, the LLM calls a tool, the system executes the tool, and returns the result to the LLM.
By treating tools as searchable memory rather than static instructions, the agent can scale to thousands of tools without ever suffering from context bloat.
Memory Unit Augmentation: Perfecting the Semantic Search
Moving tool definitions out of the context window and into a vector database solves the problem of Context Bloat. However, it introduces a new engineering challenge: raw developer-written tool descriptions are often terse and lack the semantic richness required for a vector database to reliably distinguish between them during a user query.
If an agent has three different database-querying tools, a basic similarity search might pull the wrong one. To guarantee that the LLM retrieves the exact right procedural memory, engineers utilize a technique called Memory Unit Augmentation.
The Augmentation Pipeline
Instead of directly embedding the raw code descriptions, the system adds an active preprocessing step where the LLM itself rewrites the memory units before they are ever stored.
Here is the exact architectural flow of how tools are augmented into high-fidelity memory units:
- LLM Enhancement: The raw natural language processing (NLP) tool definitions — which include the tool’s Name, Description, and required Parameters — are first passed through the LLM. The LLM is instructed to expand and enhance these definitions, adding rich contextual keywords and usage scenarios.
- Encoding: Once the LLM has enriched the text, these augmented tool definitions are passed into the Embedding Model to be encoded.
- Database Loading: Finally, the mathematically encoded, augmented tool definitions are loaded into the database (DB).
The Engineering Advantages (The “Pros”)
By forcing the LLM to rewrite the NLP tool definitions before vectorizing them, the system unlocks Enhanced Semantic Search Operations. This LLM-augmented tool retrieval provides several massive mathematical advantages in production:
- Better Separability: In the high-dimensional vector space, the expanded descriptions push similar but distinct tools further apart. This creates much better separability between the tools, preventing the system from confusing a “delete_user” tool with an “update_user” tool.
- Higher Recall and High Signal: The process generates a high-signal embedding text. Because the text was actively shaped by an LLM, the resulting vectors have better characteristics and are significantly more discernible by the embedding model during a similarity search.
By augmenting the memory units before storage, developers ensure that when the agent searches its procedural memory, it recalls the exact right tool for the job with near-perfect reliability.
Mastering Context Engineering: The Art of Window Reduction
As an AI agent operates over days or weeks, its raw interactions generate massive amounts of data. For an agent to truly learn, this raw interaction data must be transformed into durable knowledge. To achieve this, the architecture relies on autonomous write-back loops that allow the agent to extract structured facts from conversations, continuously update itself, and consolidate volatile episodic memory into long-term semantic memory .
However, this creates a profound engineering bottleneck. You cannot simply feed weeks of consolidated memory into the LLM for every new query. To solve this, developers rely on the practice of Context Engineering — specifically, the rigorous process of Context Window Reduction.
Context Window Reduction is the process of shrinking the amount of information placed in an LLM’s context window by summarizing, compressing, de-duplicating, and filtering content, all while strictly preserving the critical signals needed for the current task .
To execute this reduction, architects employ 2 Main Techniques:
- Context Summarization
- Context Compaction
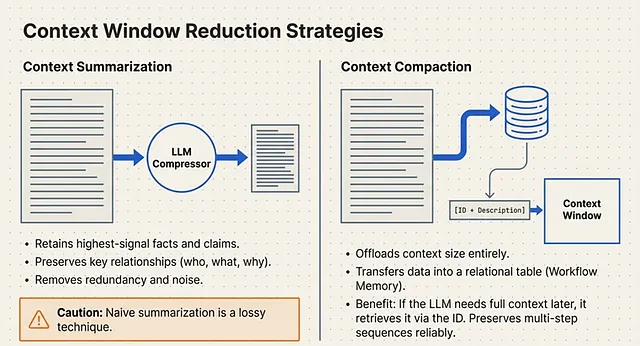
Technique 1: Context Summarization (The “Lossy” Path)
Context Summarization is the active process of taking the whole context of a text and running it through an LLM to compress the content into a shorter representation. The goal is to preserve the most salient, task-relevant information from the original data .
When engineering a summarization pipeline, the LLM is instructed to perform three specific filtering actions:
- Retain: Keep only the highest-signal, task-relevant facts and claims.
- Preserve: Maintain the core meaning and key relationships (e.g., who did what, why they did it, the specific results, and any caveats).
- Remove: Aggressively strip out redundancy, low-value detail, and general noise.
The Execution Flow of Summarization
In practice, this means taking all the disparate elements that normally bloat a prompt — the System Instructions, Knowledge Base Docs, Tool Memory, Entity Memory, Workflow Memory, Conversational Memory, and the User Prompt — and passing them entirely through a summarization LLM .
The output is a highly compressed block of summarized content that is then injected into a clean context window for the primary reasoning LLM. For certain tasks, retrieving these summaries via semantic search provides the reasoning LLM with incredibly high-signal context without hitting token limits.
The Architectural Trade-off
While highly effective for reducing token counts, engineers must account for a fundamental flaw: naive summarization is inherently a lossy technique . Because the data is being compressed, we may always lose some granular, potentially vital information during the translation .
Because Summarization inherently loses some data, high-reliability systems also rely on the second technique: Context Compaction.
Technique 2: Context Compaction (The DB Path)
Because Context Summarization is inherently “lossy,” a robust memory architecture must also employ Context Compaction. Rather than running data through an LLM to shrink it, compaction physically removes the heavy data payload from the context window entirely and transfers that data into the external database .
Think of this as an external addition to the LLM. By offloading a massive amount of context size to the DB, the system frees up critical token space.
However, the LLM still needs to know this data exists. To achieve this, the architecture complements the compacted information with a unique ID and a brief Description . If the LLM wants a general idea of the compacted content during a reasoning step, it reads the short description in its prompt. If it explicitly needs the granular details, it uses the ID to query the DB and pull the full text back into working memory.
Workflow Memory: Preserving Execution States
This database-backed architecture doesn’t just store conversational facts; it is critical for establishing Workflow Memory.
When an agent executes a complex query, it often requires a multistep process. Without memory, the LLM has to figure out what to do on each request on the fly. Workflow memory streamlines and preserves the sequence of required steps.
By storing this multistep process, the database aids the LLM by explicitly telling it what to do on subsequent requests. This grants the agent the powerful ability to persist and reuse both the state and the structure of its work over time. As a result, multistep tasks can be reliably continued, reused, resumed, audited, or repeated .
At the database level, this is handled using Relational Tables. The DB stores discrete info about the steps and the exact timestamps of when these steps were executed, alongside embedding all the steps for semantic retrieval .
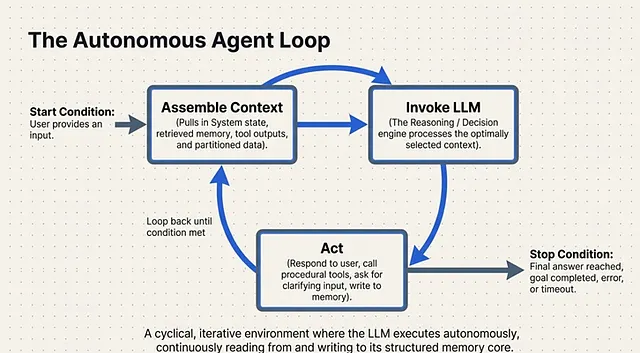
The Synthesis: The Autonomous Agent Loop
All of the architectural components we have discussed — from the external RAG databases and procedural tool embeddings to context compaction and workflow memory — culminate in the core execution engine: The Agent Loop.
The Agent Loop is a cyclical, iterative environment in which the LLM executes its logic over a specific amount of time . It operates under strict state conditions:
- Start Condition: The loop kicks off the moment a user provides an input.
Once triggered, the system enters the iterative cycle:
- Assemble Context: The system gathers all necessary components. It pulls the static instructions, queries the vector DB for relevant memory and tools, and gathers any pending data or tool outputs.
- Invoke LLM: The fully assembled, optimized context window is passed to the LLM, which acts as the reasoning engine to decide the next move.
- Act: Based on the LLM’s decision, the system executes an action. This could be generating a response, calling external tools (via procedural memory), or explicitly asking the user for clarifying input.
- Stop Condition: The cyclical loop continues until a termination state is reached. This occurs when a final answer is generated, the overarching goal is completed, a timeout or error occurs, or the agent must pause to ask the user for manual input.
Building an AI agent that operates for weeks requires abandoning the stateless paradigm. By engineering a dedicated Agent Memory Core, treating tools as retrievable procedural memory, and strictly managing the context window through summarization and compaction, developers can build systems that don’t just respond to prompts — they learn, adapt, and autonomously execute complex workflows.
Memory is not a feature — it is the system.
Any agent architecture that treats memory as optional will fail under scale.
The shift from prompt engineering to memory engineering is the real transition in building autonomous AI.
Stay ahead of the
industrial curve.
Get our quarterly executive review of Industry 5.0 shifts and architectural breakthroughs.
Zero spam. Pure industrial intelligence.